
Cross-model benchmark
Run the same prompt through two or more models side by side and score the results.
Example runs
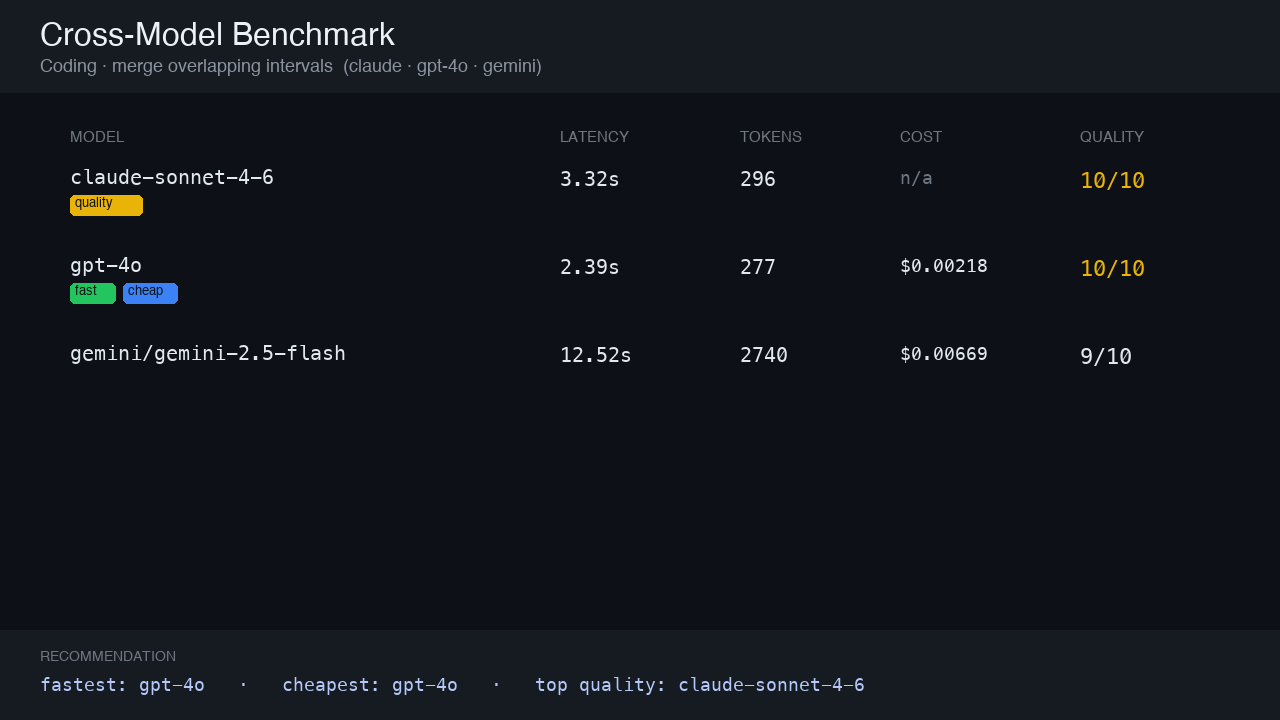
Coding prompt — merge intervals
Three models implement merge_intervals(). gpt-4o fastest + cheapest; claude and gpt tie at quality 10; gemini-2.5-flash verbose and slower.
Inputs
Acceptance checklist
5/5 checks passed.- Setup
- Preflight
- Run
- Judge
- Report
Runbook
| version | 1.0.0 |
| evaluation | programmatic |
| agent | claude-code |
| model | claude-sonnet-4-6 |
| model_provider | anthropic |
| snapshot | python312-uv |
| primary_outputs | benchmark.md |
Cross-Model Benchmark — Agent Runbook
Converted, with attribution, from Garry Tan's
benchmark-modelsskill (github.com/garrytan/gstack, MIT). The original wraps thegstack-model-benchmarkbinary + the Claude/Codex/Gemini CLIs; this runbook re-implements the same idea as a self-contained, provider-agnostic benchmark via litellm, so it runs anywhere.
EXECUTE THIS RUNBOOK NOW. Run the benchmark with tools and write every deliverable to
{{results_dir}}. This is a task to perform, not a document to summarize. Your first action is a tool call (Step 1).
Inputs (already provided)
- Prompt: the first
*.txt/*.mduploaded into/app/assets/, or the{{prompt}}parameter if no file is present. - Models: {{models}} — comma-separated litellm model ids (e.g.
claude-sonnet-4-6,gpt-4o,gemini/gemini-2.0-flash). - System prompt (optional): {{system_prompt}}
- Judge: {{judge}} (
true= score each output 0–10 with an LLM judge).
Objective
Run the same prompt through two or more models side by side and answer "which model is actually best for this task?" with data instead of vibes. For each model, measure latency, tokens (prompt + completion), and cost, capture the output, and — when the judge is on — score output quality 0–10. Then recommend the fastest, cheapest, highest-quality, and best-overall model, surfacing the tradeoff the user has to make. Models that error (bad key, quota, timeout) are skipped cleanly and reported, never aborting the batch — a benchmark with one provider down is still useful.
This is the provider-agnostic engine behind "model shootouts": pick the right model for a prompt, a skill, or a workload, and catch quality/cost regressions when providers ship new versions.
REQUIRED OUTPUT FILES (MANDATORY)
You MUST write all of the following to {{results_dir}}. The task is NOT complete until
every file exists and is non-empty. No exceptions.
| File | Description |
|---|---|
{{results_dir}}/benchmark.md | The comparison report: a per-model table (latency / tokens / cost / quality) and the fastest / cheapest / highest-quality / best-overall recommendation. The headline deliverable. |
{{results_dir}}/results.json | Full structured results — one object per model with metrics, the raw output, judge score/reason, and any error. |
{{results_dir}}/summary.md | Executive summary: models run vs skipped, the recommendation, and the cost of the benchmark itself. |
{{results_dir}}/validation_report.json | Stage-by-stage validation with overall_passed. See Step 6. |
If you finish but have not written all files, go back and write them first.
Parameters
| Parameter | Template Variable | Default | Description |
|---|---|---|---|
| Results directory | {{results_dir}} | /app/results (Jetty) / ./results (local) | Output directory |
| Prompt | {{prompt}} | (empty → use the uploaded file) | Inline prompt text (used only if no file is uploaded) |
| Models | {{models}} | claude-sonnet-4-6,gpt-4o,gemini/gemini-2.0-flash | Comma-separated litellm model ids |
| System prompt | {{system_prompt}} | (empty) | Optional system prompt sent to every model |
| Judge | {{judge}} | true | true to score each output 0–10 with an LLM judge |
| Judge model | {{judge_model}} | claude-sonnet-4-6 | The model used as the quality judge |
Dependencies
| Dependency | Type | Required | Description |
|---|---|---|---|
litellm | Python package | Yes | One API across Anthropic / OpenAI / Gemini / OpenRouter; gives token usage + cost |
| At least one provider key | Credential | Yes | ANTHROPIC_API_KEY / OPENAI_API_KEY / GEMINI_API_KEY / OPENROUTER_API_KEY (Jetty trial keys cover the first three on the platform) |
Step 1: Environment Setup & Provider Preflight
python -m pip install --quiet "litellm>=1.40"
mkdir -p "{{results_dir}}"
echo "Provider keys present:"
for k in ANTHROPIC_API_KEY OPENAI_API_KEY GEMINI_API_KEY OPENROUTER_API_KEY; do
[ -n "${!k}" ] && echo " $k: SET" || echo " $k: (absent)"
donePreflight (the dry-run, from the source skill): map each requested model to its
provider and check the key is present. Models whose provider key is absent are reported as
skipped: no_key and excluded — they do not abort the run. If zero models have a
key, STOP and write a clear error (a benchmark needs at least one authed provider).
Provider inference: claude*/anthropic/* → ANTHROPIC_API_KEY; gpt*/o1*/openai/*
→ OPENAI_API_KEY; gemini* → GEMINI_API_KEY; openrouter/* → OPENROUTER_API_KEY.
Step 2: Resolve the Prompt
Use the first *.txt/*.md in /app/assets/; if none, use {{prompt}}. If both are
empty, STOP with an error. Record the resolved prompt source in summary.md.
Step 3: Run the Benchmark
Run the same prompt through every authed model, measuring latency, tokens, and cost. Errors are caught per-model and recorded, never raised.
import litellm, time, json, pathlib, glob
litellm.drop_params = True # tolerate provider-specific params
litellm.suppress_debug_info = True
MODELS = [m.strip() for m in "{{models}}".split(",") if m.strip()]
SYSTEM = """{{system_prompt}}""".strip()
RESULTS_DIR = "{{results_dir}}"
# Resolve the prompt
cands = sorted(glob.glob("/app/assets/*.txt") + glob.glob("/app/assets/*.md"))
PROMPT = pathlib.Path(cands[0]).read_text() if cands else """{{prompt}}"""
PROMPT = PROMPT.strip()
assert PROMPT, "no prompt provided"
def msgs():
m = []
if SYSTEM and SYSTEM != "{{" + "system_prompt}}":
m.append({"role": "system", "content": SYSTEM})
m.append({"role": "user", "content": PROMPT})
return m
results = []
for model in MODELS:
rec = {"model": model}
try:
t0 = time.perf_counter()
resp = litellm.completion(model=model, messages=msgs(), timeout=180)
dt = time.perf_counter() - t0
out = resp.choices[0].message.content or ""
u = resp.usage
try:
cost = litellm.completion_cost(completion_response=resp)
except Exception:
cost = None
rec.update({"ok": True, "latency_s": round(dt, 2),
"prompt_tokens": getattr(u, "prompt_tokens", None),
"completion_tokens": getattr(u, "completion_tokens", None),
"total_tokens": getattr(u, "total_tokens", None),
"cost_usd": (round(cost, 6) if cost is not None else None),
"output": out})
except Exception as e:
rec.update({"ok": False, "error": str(e)[:300]})
results.append(rec)
print(model, "->", "OK" if rec.get("ok") else "ERR")Step 4: Judge Quality (when {{judge}} is true)
For each successful output, ask the judge model to score it 0–10 on correctness, completeness, and clarity, returning strict JSON. Skip judging for models that errored.
JUDGE = "{{judge}}".strip().lower() in ("true", "1", "yes")
JUDGE_MODEL = "{{judge_model}}".strip() or "claude-sonnet-4-6"
if JUDGE:
for r in results:
if not r.get("ok"):
continue
jp = (f"Score the ANSWER below as a response to the PROMPT, 0-10, on correctness, "
f"completeness, and clarity combined.\n\nPROMPT:\n{PROMPT}\n\nANSWER:\n{r['output']}\n\n"
f'Return ONLY JSON: {{"score": <0-10 number>, "reason": "<one sentence>"}}')
try:
jr = litellm.completion(model=JUDGE_MODEL, messages=[{"role": "user", "content": jp}], timeout=120)
jt = jr.choices[0].message.content
obj = json.loads(jt[jt.find("{"): jt.rfind("}") + 1])
r["judge_score"] = obj.get("score")
r["judge_reason"] = obj.get("reason")
except Exception as e:
r["judge_score"] = None
r["judge_error"] = str(e)[:200]Step 5: Recommend & Write Outputs
ok = [r for r in results if r.get("ok")]
def pick(seq, key, best=min):
seq = [r for r in seq if r.get(key) is not None]
return best(seq, key=lambda r: r[key]) if seq else None
fastest = pick(ok, "latency_s", min)
cheapest = pick(ok, "cost_usd", min)
top_qual = pick(ok, "judge_score", max)
bench_cost = round(sum((r.get("cost_usd") or 0) for r in results), 6)
pathlib.Path(f"{RESULTS_DIR}/results.json").write_text(json.dumps(
{"prompt_chars": len(PROMPT), "models": results,
"recommendation": {"fastest": fastest and fastest["model"],
"cheapest": cheapest and cheapest["model"],
"highest_quality": top_qual and top_qual["model"]}},
indent=2, ensure_ascii=False))
# benchmark.md — the table + recommendation
def row(r):
if not r.get("ok"): return f"| {r['model']} | — | — | — | — | skipped: {r.get('error','')[:40]} |"
q = r.get("judge_score"); c = r.get("cost_usd")
return (f"| {r['model']} | {r['latency_s']}s | {r.get('total_tokens','?')} | "
f"{('$%.5f'%c) if c is not None else 'n/a'} | {q if q is not None else '—'} | ok |")
md = ["# Cross-Model Benchmark\n",
f"Prompt: {len(PROMPT)} chars · Models: {len(results)} ({len(ok)} ran) · Judge: {JUDGE}\n",
"| Model | Latency | Tokens | Cost | Quality (0-10) | Status |",
"|-------|---------|--------|------|----------------|--------|"]
md += [row(r) for r in results]
md.append("\n## Recommendation\n")
md.append(f"- **Fastest:** {fastest['model'] if fastest else 'n/a'}")
md.append(f"- **Cheapest:** {cheapest['model'] if cheapest else 'n/a'}")
if JUDGE: md.append(f"- **Highest quality:** {top_qual['model'] if top_qual else 'n/a'}")
md.append(f"- **Benchmark cost:** ${bench_cost}")
pathlib.Path(f"{RESULTS_DIR}/benchmark.md").write_text("\n".join(md))
print("wrote benchmark.md + results.json")The "best overall" is a judgment call, not a formula — state the tradeoff in summary.md
(e.g. "Gemini was 3× cheaper and nearly as fast, but Claude scored 2 points higher on
quality; pick by whether this workload is quality- or cost-bound"). Cross-model agreement
is a recommendation; the user decides.
Step 6: Evaluate & Validate
| Status | Criteria |
|---|---|
PASS | At least 2 models ran successfully; each successful model has latency + tokens recorded; benchmark.md has the table and a recommendation; (judge on) each successful model has a judge_score or a recorded judge_error. |
PARTIAL | Exactly 1 model ran (others skipped/errored) — a single-model run has no cross-model signal; or cost was unavailable for every model (pricing unknown). |
FAIL | Zero models ran, results.json is invalid, or benchmark.md lacks the table/recommendation. |
Write validation_report.json:
{
"version": "1.0.0",
"run_date": "<ISO timestamp>",
"parameters": { "models": "{{models}}", "judge": "{{judge}}" },
"stages": [
{ "name": "setup", "passed": true, "message": "litellm installed; N provider keys present" },
{ "name": "preflight","passed": true, "message": "M models authed, K skipped (no key)" },
{ "name": "run", "passed": true, "message": "R models ran, E errored" },
{ "name": "judge", "passed": true, "message": "Scored R outputs (or judge off)" },
{ "name": "report", "passed": true, "message": "All output files written" }
],
"results": { "models_requested": 0, "models_ran": 0, "models_errored": 0, "judge_enabled": true, "benchmark_cost_usd": 0 },
"overall_passed": true
}overall_passed is true iff models_ran >= 2 and every output file exists.
Step 7: Iterate (max 3 rounds)
If a model errored with a fixable cause, fix and retry only that model:
| Error | Fix |
|---|---|
AuthenticationError / missing key | The provider key isn't set — skip that model and note it; don't retry without a key. |
RateLimitError / quota (common on trial Gemini keys) | Wait briefly and retry once; if it persists, mark skipped: quota and continue. |
BadRequestError: model not found | The litellm model id is wrong for the provider — correct it (e.g. gemini/gemini-2.0-flash, not gemini-2.0-flash). |
Timeout | Raise the per-call timeout once; if it persists, record skipped: timeout. |
completion_cost raised / cost_usd null | litellm has no pricing for that model id — leave cost null and note it; don't fail the run. |
Max 3 rounds; then keep what ran and surface the rest in summary.md.
Step 8: Write Executive Summary
Write {{results_dir}}/summary.md:
# Cross-Model Benchmark — Results
## Overview
- **Date**: <ISO timestamp> · **Prompt source**: <file or inline> · **Judge**: {{judge}}
- **Models requested**: <N> · **Ran**: <R> · **Skipped/errored**: <list with reasons>
- **Benchmark cost**: $<...>
## Results
| Model | Latency | Tokens | Cost | Quality |
|-------|---------|--------|------|---------|
## Recommendation
- **Fastest** / **Cheapest** / **Highest quality**: <...>
- **Best overall**: <judgment + the tradeoff the user must make>
## Notes / Limitations
<e.g. Gemini skipped (trial quota); cost unavailable for model X (no pricing).>Final Checklist (MANDATORY — do not skip)
Verification Script
echo "=== FINAL OUTPUT VERIFICATION ==="
RESULTS_DIR="{{results_dir}}"
for f in "$RESULTS_DIR/benchmark.md" "$RESULTS_DIR/results.json" "$RESULTS_DIR/summary.md" "$RESULTS_DIR/validation_report.json"; do
[ -s "$f" ] && echo "PASS: $f ($(wc -c < "$f") bytes)" || echo "FAIL: $f is missing or empty"
done
python3 - <<PY
import json
d = json.load(open("$RESULTS_DIR/results.json"))
ran = [m for m in d["models"] if m.get("ok")]
print(f"PASS: {len(ran)} models ran" if len(ran) >= 2 else f"WARN: only {len(ran)} model ran (no cross-model signal)")
for m in ran:
assert m.get("latency_s") is not None and m.get("total_tokens") is not None, f"missing metrics: {m['model']}"
print("PASS: all ran models have latency + tokens")
PY
echo "=== VERIFICATION COMPLETE ==="Checklist
- At least 2 models ran (or the run is honestly marked PARTIAL with the reason)
- Each ran model has latency + tokens; cost where pricing is known
-
benchmark.mdhas the per-model table and a fastest/cheapest/quality recommendation -
results.jsonis valid and includes each model's raw output + any error -
summary.mdnames the best-overall tradeoff, not just a single winner - Skipped/errored models are reported with a reason (no silent drops)
-
validation_report.jsonhasstages,results,overall_passed
If ANY item fails, go back and fix it. Do NOT finish until all items pass.
Tips
- Never benchmark without the preflight. Check provider keys first (the source skill's dry-run). A model with no key is skipped cleanly, never an aborted batch.
- One provider down is still a benchmark. Trial Gemini keys often have zero quota —
record
skipped: quotaand compare the rest; don't fail the run. - Cost can be
null. litellm only computes cost for model ids it has pricing for. A null cost is a known gap, not a failure — report it. - The judge is the point, but it costs. Quality is why you benchmark; the judge adds a little cost per model. Keep it on unless the user only cares about speed/cost.
- Best-overall is a tradeoff, not a number. Name what the user is trading (e.g. "2× the cost for +1.5 quality points"). Cross-model agreement is a recommendation; the user decides.
- Use the same prompt verbatim for every model — any difference invalidates the
comparison. Send the same
system_promptto all, too.