
SEO audit
Crawl a site, score each page against on-page SEO checks, and rank the fixes by impact.
Example runs
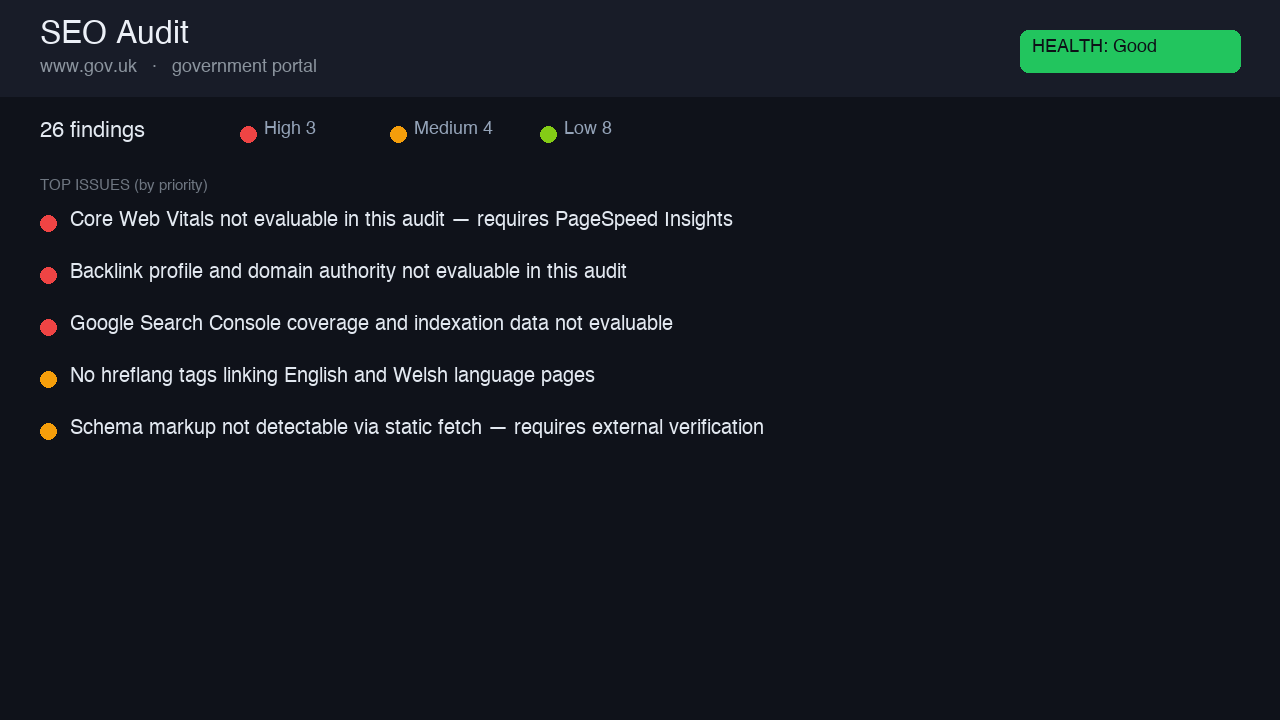
gov.uk — government portal
A strong, server-rendered government site. Health: Good. Real gaps (no English↔Welsh hreflang, short homepage meta) plus honest 'requires external tool' flags for Core Web Vitals / schema / Search Console.
Inputs
Acceptance checklist
10/10 checks passed.- seo_audit_report.md exists with Executive Summary, Technical, On-Page, and Content sections
- technical_findings.json contains structured findings array
- onpage_findings.json contains structured findings array
- content_findings.json contains structured findings array
- summary.md exists with top 3–5 priority issues and quick wins
- validation_report.json exists with stages, results, and overall_passed
- All schema markup findings used Rich Results Test or browser tool (not just curl)
- Site-type-specific checklist applied
- Prioritized action plan written
- Verification script printed PASS for every line
Runbook
| version | 1.1.0 |
| evaluation | programmatic |
| agent | claude-code |
| model | claude-sonnet-4-6 |
| model_provider | anthropic |
| snapshot | python312-uv |
| primary_outputs | seo_audit_report.md |
SEO Audit — Agent Runbook
EXECUTE THIS RUNBOOK NOW. Audit the site with tools and write every deliverable to
/app/results. This is a task to perform, not a document to summarize. Your first action is a tool call (Step 1).
Inputs (already provided — do NOT ask the user)
Audit with the values below. Do not pause to interview the user — infer the site type from the homepage, and for anything you can't determine (Search Console data, analytics, backlinks), mark it "requires external access — not evaluated" in the report rather than asking or guessing.
- Target URL: {{target_url}}
- Scope: {{scope}} (default
full) - Site type: {{site_type}} (default: auto-detect from the homepage)
- Competitor URLs: {{competitor_urls}}
Sandbox tooling note. This run has
curl/HTTP fetch but not PageSpeed Insights, the Rich Results Test, Search Console, Screaming Frog, or Ahrefs. Do a thorough static audit (robots.txt, sitemaps, titles/meta/H1s, canonicals, hreflang, internal links, alt text, HTTPS) and explicitly flag the checks that need those external tools as "requires external tool" — never report a pass/fail you could not actually verify.
Objective
You are an expert in search engine optimization. Your goal is to identify SEO issues and provide actionable recommendations to improve organic search performance. This runbook guides the agent through a systematic, prioritized SEO audit covering crawlability, technical foundations, on-page optimization, content quality, and authority signals. The audit adapts to the site type (SaaS, e-commerce, blog, multilingual, local) and produces a structured report with evidence-backed findings and a prioritized action plan. Use this runbook whenever the user mentions "SEO audit," "technical SEO," "why am I not ranking," "page speed," "core web vitals," "crawl errors," "indexing issues," or any vague request like "my SEO is bad."
REQUIRED OUTPUT FILES (MANDATORY)
You MUST write all of the following files to /app/results.
The task is NOT complete until every file exists and is non-empty. No exceptions.
| File | Description |
|---|---|
/app/results/seo_audit_report.md | Full SEO audit report with all findings and prioritized action plan |
/app/results/technical_findings.json | Structured technical SEO findings (issue, impact, evidence, fix, priority) |
/app/results/onpage_findings.json | Structured on-page SEO findings |
/app/results/content_findings.json | Structured content quality findings |
/app/results/summary.md | Executive summary with top 3–5 priority issues and quick wins |
/app/results/validation_report.json | Structured validation results with stages, results, and overall_passed |
If you finish your analysis but have not written all files, go back and write them before stopping.
Parameters
| Parameter | Default | Description |
|---|---|---|
| Results directory | /app/results | Output directory for all results |
| Site URL | (required) | The root URL of the site to audit (e.g. https://example.com) |
| Audit scope | full | full for technical + on-page + content, or technical, on-page, content for focused audits |
| Site type | (inferred) | saas, ecommerce, blog, multilingual, local — drives common-issues checklist |
| Search Console access | false | Whether the user has granted Search Console access |
| Competitor URLs | (optional) | Comma-separated list of top organic competitors |
Dependencies
| Dependency | Type | Required | Description |
|---|---|---|---|
curl / web_fetch | CLI / tool | Yes | Fetch page HTML for technical analysis (note: cannot detect JS-injected schema) |
| Google Search Console | External service | Recommended | Coverage, Core Web Vitals, and indexation data |
| Google PageSpeed Insights | External service | Yes | Core Web Vitals and speed diagnostics |
| Rich Results Test | External service | Yes | Schema validation (renders JavaScript — use instead of curl) |
| Screaming Frog | External tool | Optional | Full crawl for large sites; renders JavaScript for schema detection |
| Ahrefs / Semrush | External tool | Optional | Backlink profile and competitor analysis |
Step 1: Environment Setup
# The target URL comes from the Inputs block above (substituted from the run parameters),
# NOT from an environment variable.
SITE_URL="{{target_url}}"
if [ -z "$SITE_URL" ] || [ "$SITE_URL" = "{{target_url}}" ]; then
echo "ERROR: no target_url was provided to this run"
exit 1
fi
# Confirm site is reachable
HTTP_STATUS=$(curl -s -o /dev/null -w "%{http_code}" --max-time 15 "$SITE_URL")
if [ "$HTTP_STATUS" != "200" ] && [ "$HTTP_STATUS" != "301" ] && [ "$HTTP_STATUS" != "302" ]; then
echo "WARNING: $SITE_URL returned HTTP $HTTP_STATUS — proceed with caution"
fi
# Create output directory
mkdir -p /app/results
echo "Auditing: $SITE_URL"
echo "HTTP status: $HTTP_STATUS"Establish context from the site itself (do not ask the user):
- Site type — infer from the homepage (
{{site_type}}if provided, else auto-detect: SaaS, e-commerce, blog/content, multilingual, local). This drives the Step 5 checklist. - Scope —
{{scope}}(defaultfull: technical + on-page + content). - Priorities & competitors — use
{{competitor_urls}}if provided; otherwise infer the primary topics from the homepage and key pages. - External data — Search Console / analytics / backlink tools are not available in this run; mark any check that needs them "requires external access — not evaluated."
Step 2: Technical SEO Audit
Work through the technical checklist in priority order. For each finding, record: issue, impact (High/Medium/Low), evidence, fix, and priority (1–5).
Schema Markup Detection Limitation
web_fetchandcurlcannot reliably detect structured data / schema markup.Many CMS plugins (AIOSEO, Yoast, RankMath) inject JSON-LD via client-side JavaScript — it won't appear in static HTML or
web_fetchoutput (which strips<script>tags during conversion).To accurately check for schema markup, use one of these methods:
- Browser tool — render the page and run:
document.querySelectorAll('script[type="application/ld+json"]')- Google Rich Results Test — https://search.google.com/test/rich-results
- Screaming Frog export — if the client provides one, use it (SF renders JavaScript)
Priority Order
- Crawlability & Indexation — can Google find and index the site?
- Technical Foundations — is the site fast and functional?
- On-Page Optimization — is content optimized?
- Content Quality — does it deserve to rank?
- Authority & Links — does it have credibility?
2a: Crawlability
# Fetch robots.txt
curl -s "$SITE_URL/robots.txt"
# Check sitemap reference and accessibility
curl -s "$SITE_URL/sitemap.xml" | head -50Robots.txt checklist:
- No unintentional blocks on important pages
- Sitemap URL referenced
- Important directories allowed
XML Sitemap checklist:
- Exists and accessible at
/sitemap.xml(or referenced in robots.txt) - Contains only canonical, indexable URLs
- Submitted to Google Search Console
- No 404s, redirects, or noindex URLs included
- Updated regularly
Site Architecture:
- Important pages within 3 clicks of homepage
- Logical hierarchy with no orphan pages
- Internal linking supports crawl paths
Crawl Budget (large sites only):
- Parameterized URLs controlled (via robots.txt or canonical)
- Faceted navigation handled (noindex or canonical)
- Session IDs not in URLs
2b: Indexation
# Quick index count check (manual verification via Google)
echo "Check: site:$(echo $SITE_URL | sed 's|https\?://||')"
# Check canonical tags
curl -s "$SITE_URL" | grep -i 'canonical'
# Check noindex directives
curl -s "$SITE_URL" | grep -i 'noindex'Indexation checklist:
- All important pages indexed (verify via Search Console Coverage report)
- No important pages with noindex tags
- Canonicals point in the correct direction
- No redirect chains or loops
- No soft 404s on important URLs
- No duplicate content without canonicals
- HTTP → HTTPS canonical consistency
- www vs. non-www consistency
- Trailing slash consistency
2c: Site Speed & Core Web Vitals
Check via Google PageSpeed Insights (https://pagespeed.web.dev/) for the primary page types (homepage, key landing pages, blog posts).
Core Web Vitals targets:
| Metric | Good | Needs Improvement | Poor |
|---|---|---|---|
| LCP (Largest Contentful Paint) | < 2.5s | 2.5s–4s | > 4s |
| INP (Interaction to Next Paint) | < 200ms | 200ms–500ms | > 500ms |
| CLS (Cumulative Layout Shift) | < 0.1 | 0.1–0.25 | > 0.25 |
Speed factors to audit:
- Server response time (TTFB) < 600ms
- Images optimized (compressed, WebP format, lazy-loaded, responsive)
- JavaScript execution not blocking render
- CSS delivered efficiently (no render-blocking)
- Caching headers set correctly
- CDN in use
- Fonts loaded efficiently (font-display: swap)
2d: Mobile-Friendliness
- Responsive design (not a separate m. subdomain)
- Tap targets sufficiently sized (≥ 48px)
- Viewport meta tag configured
- No horizontal scroll on mobile
- Same content served on mobile as desktop (mobile-first indexing)
2e: Security & HTTPS
curl -sI "$SITE_URL" | grep -i 'location\|strict-transport'- Entire site served over HTTPS
- Valid, unexpired SSL certificate
- No mixed content (HTTP resources on HTTPS pages)
- HTTP → HTTPS redirects in place
- HSTS header present (bonus)
2f: URL Structure
- URLs are readable and descriptive
- Keywords appear in URLs where natural
- Consistent URL structure site-wide
- No unnecessary parameters
- Lowercase and hyphen-separated
2g: International SEO & Hreflang (skip if single-language site)
Hreflang checklist:
- Self-referencing entry on every page
- Reciprocal links (if A points to B, B must point back to A)
- Valid ISO 639-1 language codes + optional ISO 3166-1 Alpha-2 region (e.g.,
en-GB, NOTen-UK) -
x-defaultpresent pointing to fallback - All hreflang target URLs return 200, are indexable, and match their canonical
- No duplicate language-region codes pointing to different URLs
- Canonical URL appears in the hreflang set (if not, all hreflang is silently ignored)
- HTML and sitemap annotations agree (conflicting signals cause Google to drop the pair)
Locale URL structure:
- Recommended: subdirectories (
/en/,/ar/) - Acceptable: subdomains or ccTLDs
- Not recommended: URL parameters (
?lang=en)
Step 3: On-Page SEO Audit
Analyze key page types: homepage, top landing pages, representative blog/content posts.
3a: Title Tags
curl -s "$SITE_URL" | grep -i '<title>'- Unique titles for each page
- Primary keyword near the beginning
- 50–60 characters (visible in SERP)
- Compelling and click-worthy
- Brand name at end
Common issues: duplicate titles, truncated titles (> 60 chars), keyword stuffing, missing titles.
3b: Meta Descriptions
curl -s "$SITE_URL" | grep -i 'meta.*description'- Unique description per page
- 150–160 characters
- Includes primary keyword
- Clear value proposition with call to action
Common issues: duplicate descriptions, auto-generated content, too long/short, no compelling reason to click.
3c: Heading Structure
- Exactly one H1 per page containing the primary keyword
- Logical hierarchy: H1 → H2 → H3 (no skipped levels)
- Headings describe content, not just styling
- No page lacks an H1
3d: Content Optimization
- Primary keyword appears in the first 100 words
- Related keywords used naturally throughout
- Content depth sufficient for the topic
- Content satisfies the search intent (informational / transactional / navigational)
- Better than or comparable to top-ranking competitors
Thin content red flags:
- Pages with minimal unique content
- Tag/category pages with no added value
- Doorway pages
- Duplicate or near-duplicate content across URLs
3e: Image Optimization
- Descriptive, keyword-relevant file names
- Alt text on all images, describing the image
- Images compressed to reasonable file sizes
- Modern formats used (WebP preferred)
- Lazy loading implemented
- Responsive images (
srcset)
3f: Internal Linking
- Important pages well-linked from other pages
- Anchor text is descriptive (not "click here")
- No broken internal links
- No orphan pages (pages with zero internal links)
- Reasonable link count per page (avoid link dilution)
3g: Keyword Targeting
Per page:
- One clear primary keyword target per page
- Title, H1, and URL aligned to that keyword
- Content satisfies search intent
- Not competing with another page for the same keyword (cannibalization)
Site-wide:
- Keyword mapping document exists or can be inferred
- No major keyword coverage gaps
- No keyword cannibalization (multiple pages targeting same term)
- Logical topical clusters
Step 4: Content Quality Assessment
4a: E-E-A-T Signals
Experience: First-hand experience demonstrated; original insights, data, or case studies present.
Expertise: Author credentials visible; information is accurate and detailed; claims are properly sourced.
Authoritativeness: Site is recognized in the space; cited by other reputable sources; industry credentials displayed.
Trustworthiness: Accurate information; transparent about business purpose; contact information available; privacy policy and terms present; site is HTTPS.
4b: Content Depth
- Comprehensive coverage of the topic
- Answers follow-up questions the user likely has
- Better than the top-ranking competitors
- Content is current (no outdated statistics, deprecated references)
4c: User Engagement Signals (if analytics access available)
- Time on page (low may indicate poor content match)
- Bounce rate in context (high bounce + low time = content mismatch)
- Pages per session
- Return visit rate
Step 5: Common Issues by Site Type
Apply the checklist for the identified site type:
SaaS / Product Sites
- Product pages have sufficient content depth
- Blog content links to relevant product pages
- Comparison / alternative pages exist for high-intent queries
- Feature pages are not thin
- Glossary or educational content present for topical authority
E-commerce
- Category pages have unique descriptive content (not just a product grid)
- Product descriptions are unique (not manufacturer copy)
- Product schema markup present and valid
- Faceted navigation controlled (noindex or canonical) to avoid duplicates
- Out-of-stock pages handled correctly (301 redirect or keep with alternatives)
Content / Blog Sites
- Outdated content identified and scheduled for refresh
- No keyword cannibalization between posts
- Topical clusters structured with pillar + cluster pages
- Internal linking connects related posts
- Author bio pages exist with credentials
Multilingual / Multi-Regional Sites
- Hreflang errors absent (missing return tags, invalid codes, no self-reference)
- No cross-locale canonicalization (suppresses indexing)
- Thin locale pages not dragging down site-wide quality signal
- All locale pages have fully translated main content (not just UI chrome)
-
x-defaultfallback declared - No IP-based redirects hiding content from Googlebot
Local Business
- NAP (Name, Address, Phone) consistent across site and directories
- Local schema (LocalBusiness) present and valid
- Google Business Profile optimized
- Location pages exist for each service area
- Local-relevant content present
Step 6: Iterate on Errors (max 3 rounds)
If any audit check is inconclusive or tool limitations blocked a finding:
- Identify the specific gap (e.g., schema not detectable via curl)
- Apply the appropriate alternative method from the Common Fixes table
- Re-run the specific check and update the finding
- Repeat up to 3 times per blocked check
Common Fixes
| Issue | Fix |
|---|---|
| Schema markup not visible via curl/web_fetch | Use Rich Results Test or browser tool — they render JavaScript |
| Hreflang errors unclear | Fetch both the source and target locale pages and compare their hreflang sets manually |
| Cannot access Search Console | Ask user to export Coverage or Core Web Vitals report as CSV |
| Redirects not visible | Use curl -L -sI to follow redirect chain and count hops |
| Core Web Vitals data missing | Use PageSpeed Insights API for programmatic access |
| Sitemap inaccessible | Check robots.txt for alternate sitemap URL; try /sitemap_index.xml |
Step 7: Generate Audit Report
Compile all findings into the structured output files.
import json, pathlib
# Structure findings
technical_findings = [
# Each finding: {"issue": "...", "impact": "High|Medium|Low", "evidence": "...", "fix": "...", "priority": 1}
]
onpage_findings = []
content_findings = []
pathlib.Path("/app/results/technical_findings.json").write_text(json.dumps(technical_findings, indent=2))
pathlib.Path("/app/results/onpage_findings.json").write_text(json.dumps(onpage_findings, indent=2))
pathlib.Path("/app/results/content_findings.json").write_text(json.dumps(content_findings, indent=2))Write the report to exactly /app/results/seo_audit_report.md (that literal filename —
not audit_report.md or any other name; it is the declared primary deliverable). Fold the
prioritized action plan into this single file rather than emitting a separate one. Use this
structure:
# SEO Audit Report — <site_url>
**Date:** <date>
**Scope:** <full|technical|on-page|content>
**Site Type:** <type>
## Executive Summary
- Overall health: <Good|Needs Attention|Critical>
- Top 3–5 priority issues
- Quick wins identified
## Technical SEO Findings
| Issue | Impact | Evidence | Fix | Priority |
|-------|--------|----------|-----|----------|
...
## On-Page SEO Findings
...
## Content Findings
...
## Prioritized Action Plan
1. Critical fixes (blocking indexation or ranking)
2. High-impact improvements
3. Quick wins (easy, immediate benefit)
4. Long-term recommendations
## Related Skills
- ai-seo: For optimizing content for AI search engines (AEO, GEO, LLMO)
- programmatic-seo: For building SEO pages at scale
- site-architecture: For page hierarchy, navigation design, and URL structure
- schema-markup: For implementing structured data
- page-cro: For optimizing pages for conversion (not just ranking)
- analytics-tracking: For measuring SEO performanceFinal Checklist (MANDATORY — do not skip)
Verification Script
echo "=== FINAL OUTPUT VERIFICATION ==="
RESULTS_DIR="/app/results"
for f in \
"$RESULTS_DIR/seo_audit_report.md" \
"$RESULTS_DIR/technical_findings.json" \
"$RESULTS_DIR/onpage_findings.json" \
"$RESULTS_DIR/content_findings.json" \
"$RESULTS_DIR/summary.md" \
"$RESULTS_DIR/validation_report.json"; do
if [ ! -s "$f" ]; then
echo "FAIL: $f is missing or empty"
else
echo "PASS: $f ($(wc -c < "$f") bytes)"
fi
done
echo "=== END VERIFICATION ==="Checklist
-
seo_audit_report.mdexists with Executive Summary, Technical, On-Page, and Content sections -
technical_findings.jsoncontains structured findings array -
onpage_findings.jsoncontains structured findings array -
content_findings.jsoncontains structured findings array -
summary.mdexists with top 3–5 priority issues and quick wins -
validation_report.jsonexists withstages,results, andoverall_passed - All schema markup findings used Rich Results Test or browser tool (not just curl)
- Site-type-specific checklist applied
- Prioritized action plan written
- Verification script printed PASS for every line
If ANY item fails, go back and fix it. Do NOT finish until all items pass.
Tips
- Schema detection requires JavaScript rendering. Never report "no schema found" based on
curlorweb_fetchalone — use Rich Results Test or the browser tool. - Hreflang reciprocity is the most common error. If page A declares a hreflang link to page B, page B must declare a return link to page A — or Google ignores both.
- Crawlability before content. Always verify Google can crawl and index the site before optimizing content — a beautiful site that's blocked in robots.txt ranks for nothing.
- Thin locale pages hurt the whole site. The helpful content system is site-wide; many thin translated pages suppress rankings for strong pages too.
- Cannibalization is easy to miss. Check that no two pages target the same primary keyword — use
site:domain.com "keyword"to spot duplicates. - Core Web Vitals vary by page type. Test the homepage, a category page, and a blog post — scores often differ significantly.
- E-commerce faceted navigation is a common duplicate-content trap. Audit
/category?color=red&size=Mstyle URLs; they must be canonicalized or excluded from indexation.